Notes of LoRA
Introduction
Inspiration: the change in weights during model adaptation have a low “intrinsic rank”
Description: Change small matrices A and B when fine-tune, adding A * B to weight W, which significantly reduce the trainable number of parameters because r << d
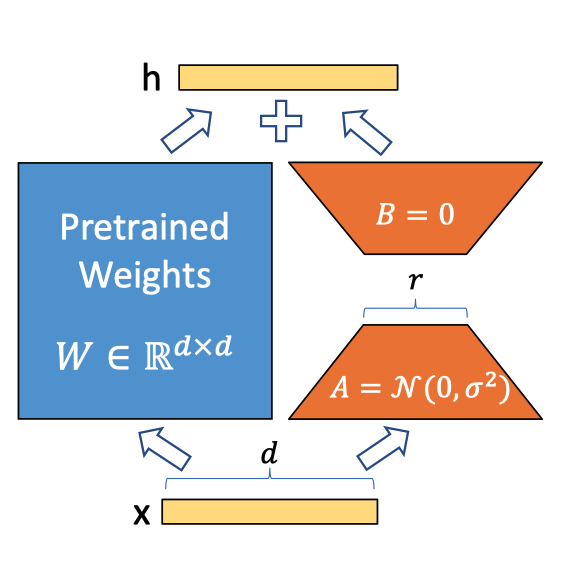
Novelty: Reducing Fine-tuen cost without additional latency and quality reduction or changing input consturction at the same time
Benefits
1) Efficiently switch models for different target tasks through switching LoRA matrices 2) Reduce consuming time and hardware requirement when Fine-tune 3) Without any inference lantency 4) Orthogonal with other adaptation method
Further information
1) LoRA have better scalability and performances

2) Adapting more weight matrices is preferable than adapting a single type of weights with a larger rank, 2 or 4 is a great option
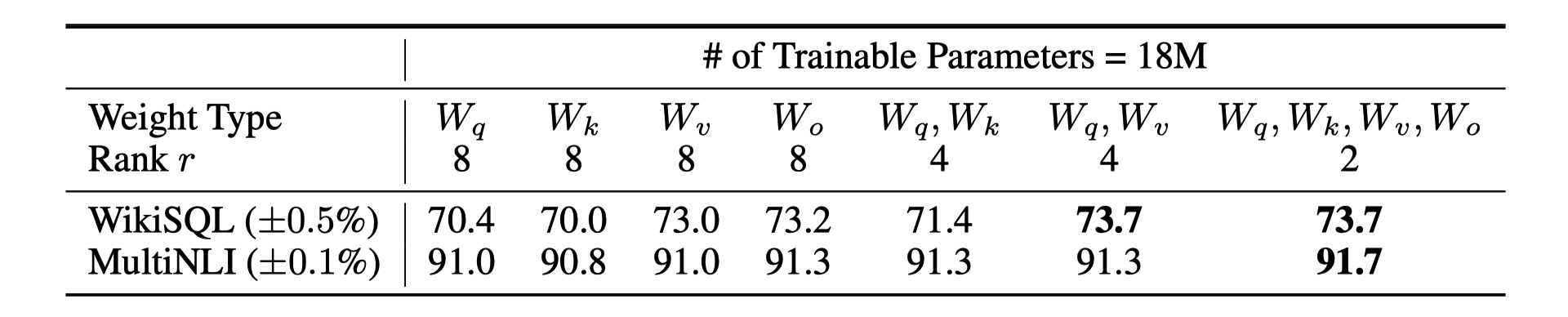
3) Similiarity of LoRA vectors among different rank(r) is higher when dimention is small, which prove (1)low-demension consists more information, (2) small r is enough
4) Matrices of LoRA is similiar with original weight mtraices, LoRA is a amplification of original information.
Summary
1) Purpose of auther? reduce the cost of fine-tuen without any loss
2) Key of new method? change of adaptation have a low “intrinsic rank”
3) What is useful for me? large Matrices in LLM have a low “intrinsic rank”? New fine-tune method
4) What references is necessary to read? Where “intrinsic rank” comes from?
- Measuring the Intrinsic Dimension of Objective Landscapes
- Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
1-4 from Andrew NG
5) new idea
rand-deficiency of delta_w suggests that w could be rank-deficient as well, which can be a source of inspiration of future of works.