GRPO
GRPO
Main idea
Key point it to understand the below pictures
Iteration steps

- for each input, generator
Goutputs - for each output, calculate logits_prob for each token in current, old, reference model
- calcualte objective value as loss
- update old model in each step
- update reference model in each epoch
Objective function
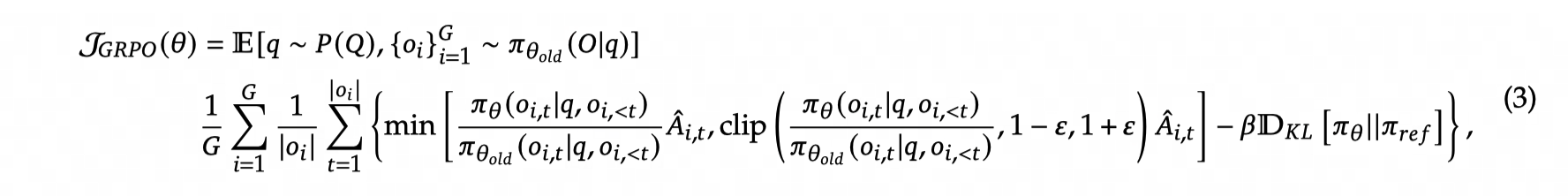
Gis amount of outputs in each group for each inputO_iis i-th output in current grouptis index of tokens inO_iqis inputO_i,tis t-tokens in i-th outputpiis model parameter
KL value
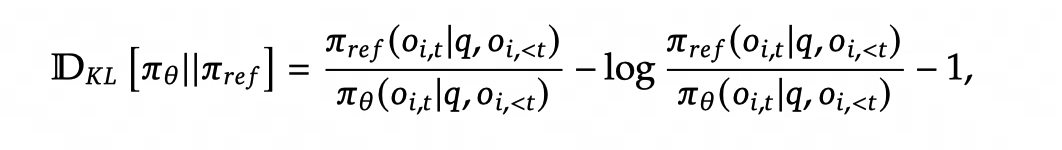
Hyper parameters
Name in huggingface-trl
betaweight for KL-value between current model and reference model, increase to avoid over-fittingnum_iterationsNumbers of iteration per batch, GRPO iterations times inAlgorithm 1 picture, similar with LRepsilonfor both clip lower_bound and upper_boundepsilon_highrepalceepsilonfor clip upper_bound when existsync_ref_modelbool, whether to Whether to synchronize the reference model with the active model everyref_model_sync_stepssteps, using theref_model_mixup_alphaparameterref_model_mixup_alphafloat, default 0.6,π_ref = α * π_θ + (1 - α) * π_ref_prevref_model_sync_stepsint, default 512, To use this parameter, you must set sync_ref_model=True.
FAQ
Q: How to cold start?
A: In first step, we know advantages for each output, which can push parameters updating to make objective value as much as possible
Q: How to simplify Zoom up/down in objective function?
This post is licensed under CC BY 4.0 by the author.