Validated example of LLM acceleration
Theory of Fast Cross Entropy Loss
As a start of LLM acceleration project, I learnt Fast Cross Entropy Loss in unsloth, it shows a better realize solution of cross entropy loss than default pytorch code.
As default, pytorch will use log_softmax to realize CE loss, it’s common for all solution, but, the target has only one valid value in the training process of LLM and other element are 0, this is the different part between LLM training and common CE, that’s why LLM acceleration solution works.
So, we can update the calculate process of CE as below
\[\begin{align*}\label{2} & CT(x, y)_i = -y_i(log(softmax(x))) \\ & =-y_i(log(p_i)) \\ & =-(log(\frac{exp(x_y)}{sum(exp(x))})) \\ & =logsumexp(x) - x_y \\ \end{align*}\]After optimizaiton, this can reduce time complexity from $O(4n)$ to $O(2n)$, which can reduce the cost of time and GPU memory for the best suitation.
This is all the theory of solution
Validation
Taking finetuning Gemma2 as example, I tried to compare the result of new CE loss and default one, but I found some thing that I have never know before.
(1) smoothed_loss
There is a smoothed_loss which is used in CE Loss except traditional log_softmax, which is the first noise during my validation.
But I also realize it throught new method.
(2) A trick that subtracting the max-logit to make softmax more stable
After I realize above code and fine-tune Gemma2, I found it can reduce fine-tune time by 4.8%, but loss of new code didn’t reduce by training step, so, I ask help in Machine Learning subreddit and get what I want.
After applying subtracting max-logit to my code, it works, there almost zero differences for loss between default pytorch code and my new code, the loss as below:
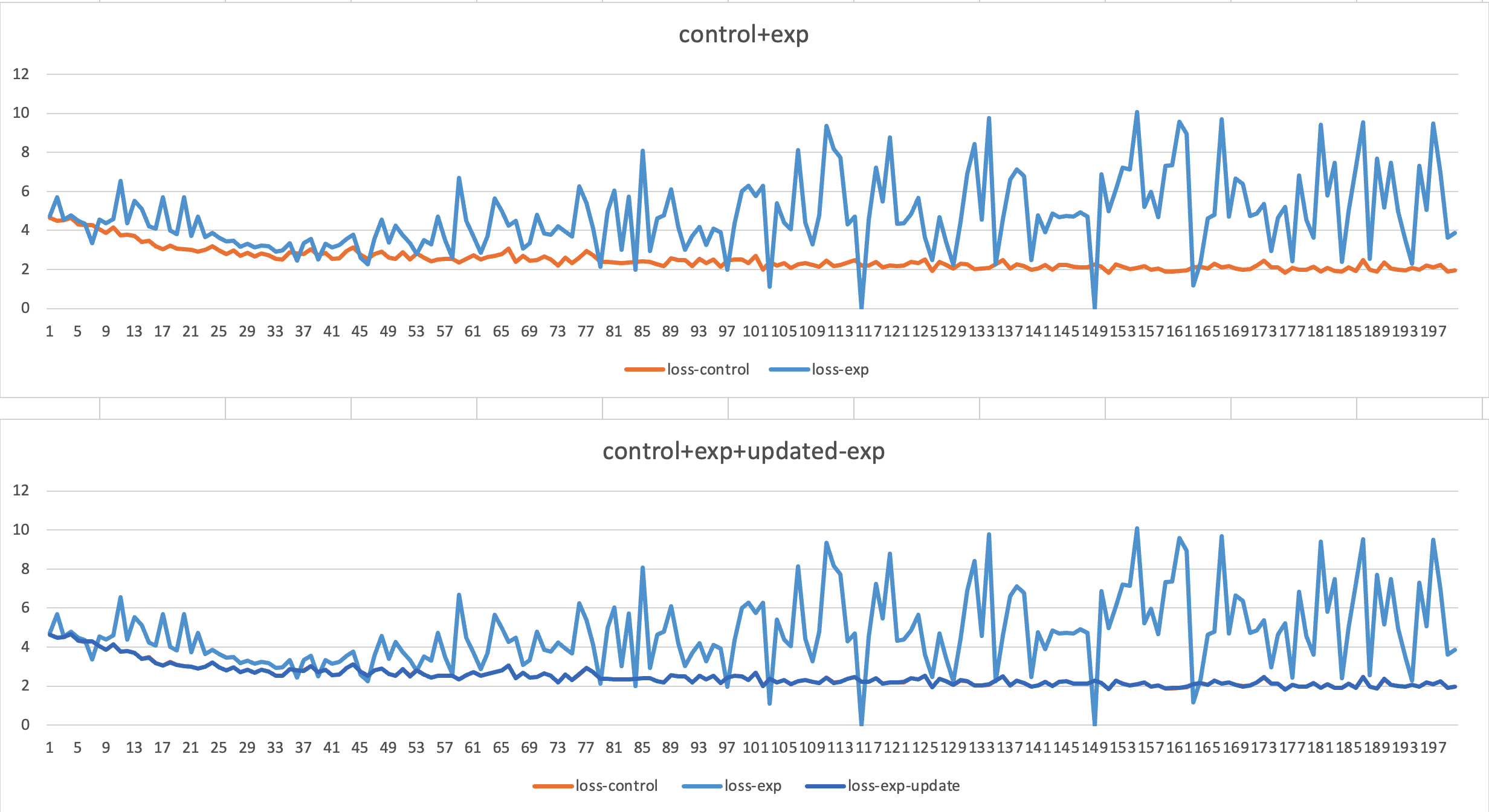
This can prove that My new code have the same result compare to default official code.
Result
default offical key code:
# time complexity 2n for subtracting max-logit
log_probs = -nn.functional.log_softmax(logits, dim=-1) # time complexity 4n
nll_loss = log_probs.gather(dim=-1, index=labels) # 1n
smoothed_loss = log_probs.sum(dim=-1, keepdim=True, dtype=torch.float32) # 1n
My new code:
logitsmax = logits.max(dim = -1)[0].unsqueeze(-1) # 1n
logsumexp = ((logits - logitsmax.repeat(1, 1, logits.shape[-1])).exp().sum(dim = -1).log()).unsqueeze(-1) + logitsmax # 3n
nll_loss = logsumexp - logits.gather(dim=-1, index=labels) # 0
smoothed_loss = (logits.shape[-1] * logsumexp - logits.sum(dim = -1, keepdim=True, dtype = torch.float32)) # 1n
PS: In theory, time complexity reduce from $8n$ to $5n$, I’m not 100% confirm this value right and it’s hard to prove that.
In terms of time cost in finetune Gemma2, I only sample 100 sample(my fault) from yahma/alpaca-cleaned and run 60 steps two times for both official code and new code.
| offical CE Loss code | New code | differences |
|---|---|---|
| 362.5s (average) | 352.5s | 2.8% |
Conclusion
I validated the new method to calculate CE Loss and reduce time cost by 2.8%.
In additional, using Triton to realize should have better performance.
This is just a example for LLM acceleration, more similiar thing can be done to accelerate the process.